RAG: The Future of Knowledge-Based Intelligent Systems
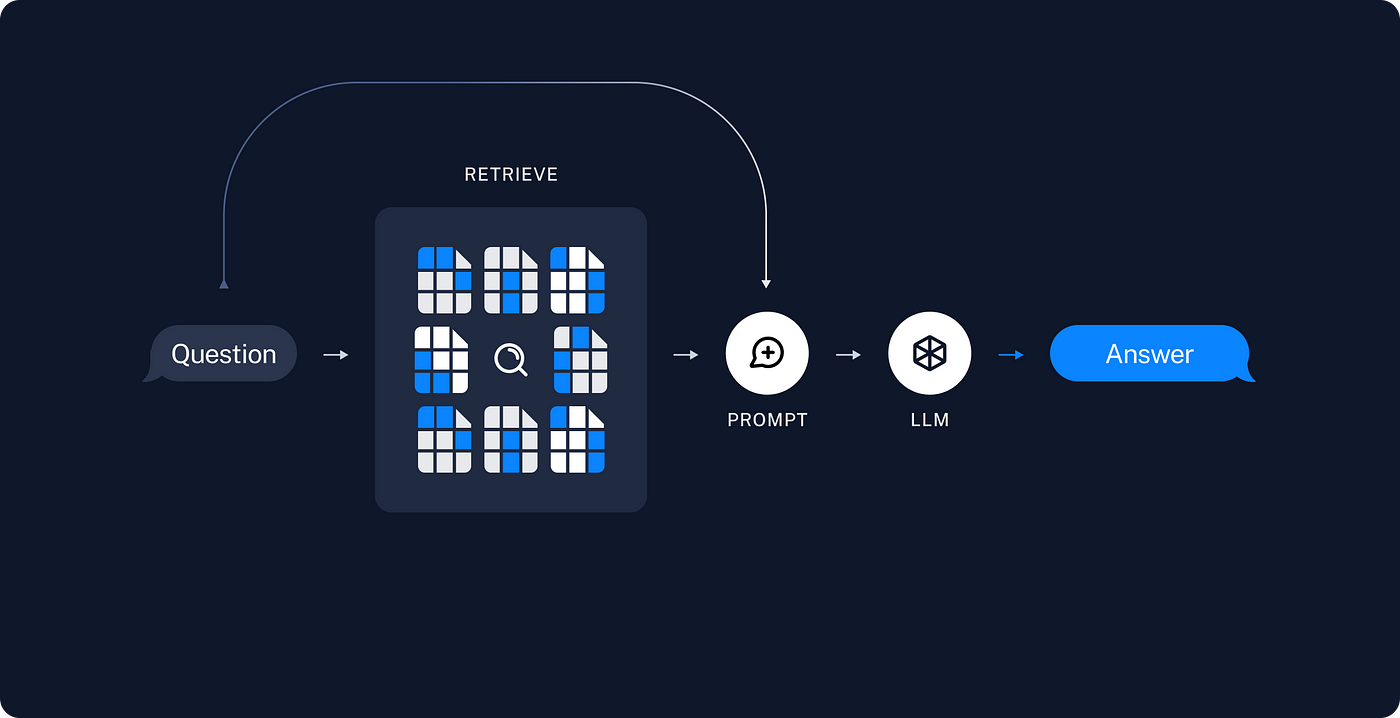
While large language models (LLMs) have revolutionized the field of natural language processing (NLP) in recent years, they still face limitations in areas such as information retrieval and data freshness. LLMs typically generate responses based on the knowledge contained in their training data, which makes them reliant on static data sources. However, when users demand dynamic, up-to-date, and context-specific information, these models often fall short.
To address these challenges, the Retrieval-Augmented Generation (RAG) method was developed. RAG integrates language models with knowledge bases, enabling access to accurate and up-to-date information. Frameworks like LangChain provide the necessary tools to implement this approach effectively.
In this article, we will delve into the core principles of RAG, explore integration techniques with LangChain, discuss practical applications, and analyze the future prospects of this transformative technology.
What is RAG and Why is it Necessary?
RAG, or Retrieval-Augmented Generation, is a method that combines two key processes: Retrieval and Generation. These steps make RAG a powerful and flexible solution:
Retrieval
- Involves fetching relevant information from a knowledge base, document set, or vector database based on the user’s query.
- Tools like FAISS, Pinecone, and ElasticSearch are used at this stage to index and query documents effectively.
Generation
- The retrieved information is processed by a language model (e.g., GPT4o, Gemini) to generate a coherent and meaningful response.
- This step ensures the contextual application of data sourced from the knowledge base.
Advantages of RAG
- Dynamic Information: Can work with up-to-date data from knowledge bases, independent of training datasets.
- Accuracy: Reduces the risk of models producing incorrect or hallucinated information.
- Flexibility: Easily adapts to various knowledge bases and document structures.

How to Implement RAG with LangChain
LangChain provides the modules and tools necessary to implement the RAG method. The process involves the following steps:
Preparing the Data Source
In RAG applications, knowledge bases can consist of document collections, structured data, or APIs. These data sources are first indexed using a vector-based search system. For example:
Document Splitting:
Documents must be divided into smaller chunks that language models can process. LangChain offers tools to streamline this process.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)Embedding Creation:
The textual representations of documents are converted into vectors using language models or custom embedding models.
from langchain_google_genai import GoogleGenerativeAIEmbeddings
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")Creating a Vector Database:
The obtained embeddings are stored in a vector database, such as FAISS, Chroma or ElasticsearchStore.
from langchain_community.vectorstores import FAISS
vector = FAISS.from_documents(documents, embeddings)Creating a Retrieval Chain
A Retrieval Chain combines the information retrieval process with response generation. This chain retrieves relevant information based on the user’s query and runs the model using that context.
from langchain.chains import create_retrieval_chain
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)Conversation Chain
Conversation Chain is a key component of LangChain that allows a language model to manage dialogues. This structure helps maintain the context of the conversation and enables the model to generate more meaningful and natural responses based on previous exchanges. ConversationChain is a powerful tool used to model a sequential communication flow consisting of a series of interactions.
Key Features of Conversation Chain:
Context Management:
Understanding and preserving the flow of conversation is crucial for effective communication. ConversationChain allows the model to “remember” previous messages and use them in subsequent responses, maintaining the context of the conversation. This ensures the conversation remains consistent and meaningful.
For example, when a user asks a new question or makes a suggestion based on previous responses, the model considers the previously provided information.
Dynamic Responses:
ConversationChain doesn’t just generate static answers; it also creates dynamic responses based on the information provided by the user. This allows the language model to manage an evolving conversation.
For instance, if a user previously inquired about the weather, the model can recall this context and address the same or related topics in future responses.
Learning Over Time:
Some ConversationChain applications have additional features that enable the model to generate more accurate responses over time, based on prior interactions. This provides an advantage in more advanced model configurations as the model is continuously optimized based on feedback.
Multi-Step Interactions:
Dialogues often involve multiple stages. ConversationChain is ideal for managing multi-step dialogues. In these interactions, the model generates responses not only for an immediate query but also for each step of a multi-phase process.
In LangChain, ConversationChain typically works integrated with a language model (e.g., Gemini, OpenAI). Each time a new input message is received, the model generates a response considering the previous messages. Let’s explore a simple example of using ConversationChain in detail:
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search\
query to look up in order to get information relevant to the conversaion")
]
)from langchain.chains import create_history_aware_retriever
retriver_chain=create_history_aware_retriever(
model, retriever, prompt
)LangChain and RAG provide a powerful toolkit that elevates the accuracy, flexibility, and efficiency of knowledge-based applications. For those looking to develop systems that work with dynamic knowledge bases, independent of training data, this combination offers a unique opportunity. In the future, as even smarter systems for information access emerge, the impact of RAG will continue to grow. This method has the potential to drive transformation not only in the field of natural language processing but across many different industries.
